近日,Mozilla的伊尼卢瓦·德博拉·拉吉(Inioluwa Deborah Raji)和纽约大学跨学科研究机构AI Now Institute的技术研究员吉纳维芙·弗里德(Genevieve Fried)就人脸识别数据研究发表了一篇名为About Face: A Survey of Facial Recognition Evaluation的论文。
论文就1976年至2019年之间的100多个脸部数据集进行研究,其研究范围包括来自超过1700万个调查对象的1.45亿张图像。《麻省理工学院技术评论》发文称该论文是“有史以来规模最大的人脸识别数据研究,并且表明了深度学习的兴起在多大程度上加剧了隐私的丧失”。
论文研究发现,在深度学习对数据的爆炸式增长的驱动下,研究人员逐渐开始不征求人们同意,从而导致越来越多的人的个人照片在他们不知情的情况下被整合到监视系统中。
论文主要确定了面部识别发展的四个历史阶段,分别为:第一阶段(1964-1995)早期研究阶段;第二阶段(1996-2006)被称为“新生物识别”的商业可行性阶段;第三阶段(2007-2013)不受限制设置的主流开发阶段;第四阶段(2014年-以后)深度学习的突破阶段。
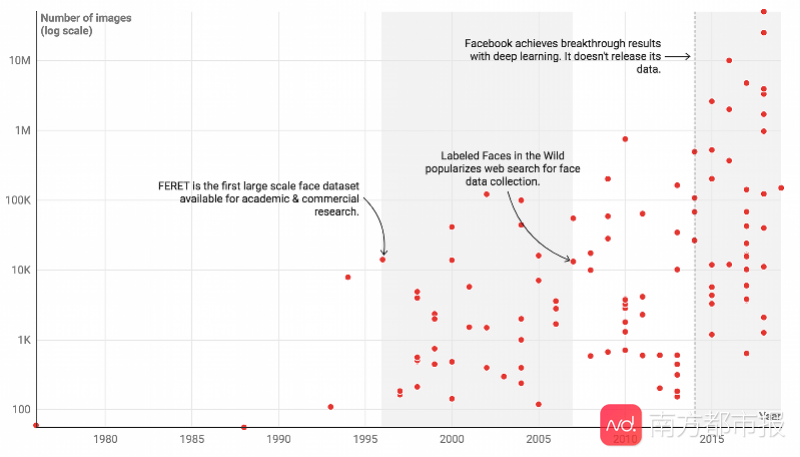
人脸识别的四大阶段:随着研究人员对技术准确性要求的不断提高,人脸识别数据集的规模呈指数增长。
外媒就该论文对人脸识别的研究,总结出了9个令人恐惧又惊讶的结果:
1.人脸识别在学术环境中的表现与实际应用之间有着巨大的鸿沟
两位作者研究该项目的最主要原因之一是,为什么人脸识别在系统测试准确率接近100%时,在现实世界中的应用依然存在严重缺陷。例如,人脸识别在识别黑人和棕色人种时准确性较差,最近也有报道显示,有三名黑人因被该技术错误识别后被相继逮捕,同时在这三起案件中,被技术错误识别的人都是黑人。
2.美国国防部对该技术的最初发展负有责任
尽管人脸识别技术的开发始于学术环境,但国防部和美国国家标准与技术研究院(NIST)于1996年将650万美元拨款投入,创建了迄今为止最大的数据集,此后这项技术开始起步。政府对这一领域很感兴趣,因为在用于监视时,它与指纹识别不同,不需要人们积极主动参与。
3.早期用于创建人脸识别数据的照片来自人像拍摄,这就产生了重大缺陷
在2000年代中期之前,研究人员积累数据库的方式是让人们坐下来拍照。由于现在的一些基本面部识别技术数据正是来自于此,所以人脸肖像技术的缺陷也产生了共鸣,即参与者类型单一并且无法准确反映现实情况的阶段设置。
4.当人像拍摄不够时,研究人员便开始抓取Google并不再征求被摄对象的同意
2007年,一个名为“野生标签的面孔(Labeled Faces in the Wild)(LFW)”数据集的出现,使研究人员开始直接从Google,Flickr和Yahoo下载图像,而无需担心是否同意,其中还包括儿童的照片。其他研究人员随后汇编的名为“LFW +”的数据集,也放宽了对未成年人的纳入标准,使用带有“婴儿”,“少年”和“青少年”等搜索词的照片来增加多样性。虽然这使照片的类型更加丰富,但它也放弃了被摄对象的隐私权。
野生标签的面孔(Labeled Faces in the Wild)(LFW)主页。
5.人脸识别的下一次繁荣来自Facebook
2014年,Facebook使用其用户照片训练了一种称为DeepFace的深度学习模型。Facebook展示了数百万张照片如何创建出更好地可以完成人脸识别任务的神经网络,从而使深度学习成为现代人脸识别的基石。
6.Facebook的大规模人脸识别活动侵犯了用户的隐私
由于Facebook利用其用户上传的照片进行人脸识别,而未征得该用户的肯定同意,由此被联邦贸易委员会(FTC)处以罚款,并向伊利诺伊州支付了一项和解金。
7.仅在公共数据集中,人脸识别就已经在1770万人的人脸上进行了训练
事实上,我们不知道在人脸识别技术发展的过程中,使用了多少人的照片,和这些人的真实身份。
8.人脸识别的自动化促生了令人反感的标签系统以及不平等的代表性
人脸识别系统已经超越了识别面部或人物的范围,他们还可以以令人反感的方式标记人物及其属性,其中就包括一些诸如“胖子”、“双下巴”、“大鼻子”、“大嘴唇”和“眼袋”等潜在侮辱性的标签。而研究也表明,人工智能中的歧视会强化现实世界中的歧视。
9.人脸识别技术的应用范围从政府监视延伸到广告定位
目前人脸识别技术不仅深耕于其本身的领域,其如今的发展也远超过1970年代其创造者的想象。论文中表明,从历史背景上可以看出,政府从一开始就促进和支持了这项技术,以便于实现刑事调查和监视。亚马逊已经将其有问题的Rekognition技术出售给了无数警察部门就是其中一个例子。
论文在结论中阐明,人脸识别技术带来了复杂的道德和技术挑战,忽视或者分解这种复杂性,对于那些部署不当的人,也包括我们自己是不利的。
作者之一的拉吉希望这篇论文能够激发研究人员思考深度学习带来的性能提升、失去共识、细致的数据验证和详尽的文档记录之间的权衡,她同时敦促那些想要继续建立人脸识别功能的人考虑开发不同的技术:“要让我们真正尝试使用该工具而又不伤及人,则需要重新设想我们所知道的一切。”
 营业执照公示信息
营业执照公示信息